0 前言
本文为初步学习神经网络同学而准备,旨在通过最简单直观的方式建立初学者对于神经网络的印象。所以本文的结论和观点主要追求简单直观,而不是严谨。
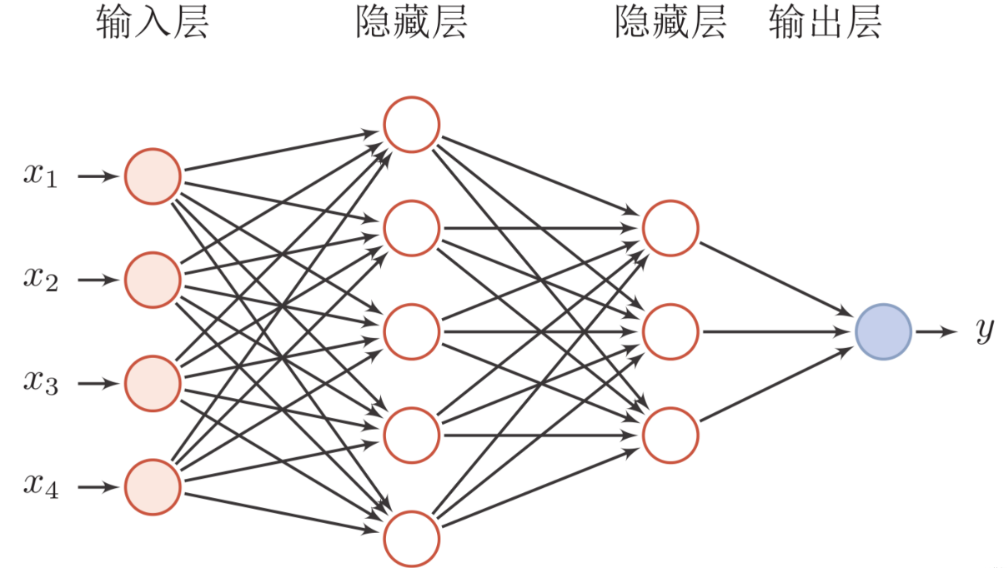
先举个简单的例子:
假设现在我们有输入 X 与对应输出 Y 的数据一堆 (X, Y) 对如下:
{ (1, 3), (2, 5), (3, 7), (4, 9), (5, 11), (6, 13), (7, 15), (8, 17), (9, 19), (10, 21) }
现在我们使用架构 f(x) = wx + b
可以发现,如果我们令 w = 2,b = 1,就能完美地拟合数据,误差损失最小。那么这个 w = 2,b = 1 就是我们想要找到的最优参数。
1 神经网络 = f(X)
神经网络本质上是一种数学模型,它通过一系列复杂的非线性变换(由不同的层和激活函数组成)来映射输入(X)到输出(Y)。
这里的 f 表示的就是这个从输入空间到输出空间的映射函数。神经网络通过学习调整其内部权重和偏置参数,以找到一个合适的函数f来逼近理想中的目标函数,从而对给定的输入 X 进行有效的预测或分类。
2 神经网络模型 = 模型架构 + 模型参数
神经网络模型是由“模型架构”和“模型参数”两个核心部分组成的。
- 模型架构:是神经网络的结构设计,包括但不限于网络的层数、每层的神经元数量、使用什么样的激活函数、网络的连接方式(例如全连接、卷积、循环等)等。模型架构决定了信息在神经网络中流动和变换的方式,以及网络能够学习到的特征的复杂度和类型。
- 模型参数:是神经网络学习过程中的可调节变量,主要包括权重(weights)和偏置(biases)。权重决定了每个神经元对前一层输出的重视程度,而偏置则是加在神经元上的一个常数项,用于调整激活函数的阈值。在训练过程中,通过优化算法(如梯度下降)调整这些参数,使得神经网络能够更好地拟合训练数据,从而在未知数据上表现得更好。
更通俗的,
- 指的是我们模型里一堆待定的数值
3 训练 = 前向传播 + 反向传播 + 参数更新
- 前向传播:在这个阶段,输入数据从输入层经过隐藏层,一路向前直到输出层,每一层的神经元都会根据当前的权重和偏置进行计算,产生该层的输出,作为下一层的输入。这一过程最终产生一个预测输出,与实际标签进行比较以评估误差。
- 反向传播:计算预测输出与真实标签之间的误差,并从输出层开始,逆向地计算每一层的误差梯度。这个过程利用链式法则,逐层计算并累积权重和偏置的梯度,以便了解如何调整这些参数来减小损失函数的值。
- 参数更新:基于反向传播得到的梯度信息,使用优化算法(如梯度下降、随机梯度下降、Adam等)来调整网络中的权重和偏置,目标是逐步减小预测误差,使模型更好地拟合训练数据。
4 训练的目的 = 更新参数
我们一直在说的训练模型中的训练,本质就是想要更新参数。通过不断更新参数来最小化预测输出与实际标签之间的差距(即损失函数的值),从而提升模型在训练数据集上的表现,并期望泛化到未见数据时也能有良好的性能。
5 前向传播 = 计算和转换特征
前向传播过程中,输入数据经过神经网络每一层的计算,包括线性变换(权重和偏置的应用)和非线性变换(通过激活函数),从而逐渐从原始特征转换为更加抽象和高级的特征表示。
6 反向传播 = 计算误差梯度
反向传播的核心任务是计算误差梯度,即损失函数相对于模型参数的导数。这一步骤对于后续的参数更新至关重要,因为它指明了参数应该如何调整以减小网络的预测误差。
7 更新参数的核心思想
标签。标签就像一个向导,指导参数往使得模型效果更好的方向走,我们希望模型的输出不断地贴近输入对应的标签

文章评论
Some truly great information, Sword lily I noticed this. "Traffic signals in New York are just rough guidelines." by David Letterman.
I was just seeking this info for a while. After six hours of continuous Googleing, finally I got it in your site. I wonder what is the lack of Google strategy that don't rank this type of informative web sites in top of the list. Generally the top websites are full of garbage.
Great V I should definitely pronounce, impressed with your web site. I had no trouble navigating through all tabs as well as related information ended up being truly easy to do to access. I recently found what I hoped for before you know it in the least. Reasonably unusual. Is likely to appreciate it for those who add forums or something, web site theme . a tones way for your customer to communicate. Nice task..
You could certainly see your enthusiasm in the paintings you write. The arena hopes for more passionate writers such as you who are not afraid to say how they believe. All the time go after your heart.
I simply could not go away your web site before suggesting that I really enjoyed the usual info an individual provide for your guests? Is going to be again often in order to inspect new posts.
You have noted very interesting points! ps decent website .
As soon as I discovered this website I went on reddit to share some of the love with them.
F*ckin¦ tremendous issues here. I am very satisfied to peer your post. Thank you so much and i am having a look forward to contact you. Will you kindly drop me a mail?
We're a gaggle of volunteers and opening a new scheme in our community. Your website offered us with helpful information to paintings on. You have performed a formidable task and our entire group will likely be grateful to you.
Hey, you used to write magnificent, but the last few posts have been kinda boring?K I miss your great writings. Past few posts are just a bit out of track! come on!
Your house is valueble for me. Thanks!…
That is very interesting, You are a very professional blogger. I have joined your rss feed and stay up for seeking more of your excellent post. Also, I have shared your website in my social networks!
Hey there! Do you know if they make any plugins to safeguard against hackers? I'm kinda paranoid about losing everything I've worked hard on. Any suggestions?
We are a bunch of volunteers and starting a new scheme in our community. Your web site offered us with valuable information to paintings on. You've done a formidable activity and our whole neighborhood will probably be grateful to you.
Today, I went to the beachfront with my kids. I found a sea shell and gave it to my 4 year old daughter and said "You can hear the ocean if you put this to your ear." She placed the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is entirely off topic but I had to tell someone!
Some truly interesting information, well written and broadly user genial.
Wow, amazing blog layout! How long have you been blogging for? you made blogging look easy. The overall look of your site is fantastic, as well as the content!
Fantastic web site. Lots of useful info here. I am sending it to a few pals ans additionally sharing in delicious. And of course, thank you on your effort!
Admiring the persistence you put into your site and detailed information you offer. It's great to come across a blog every once in a while that isn't the same unwanted rehashed information. Fantastic read! I've bookmarked your site and I'm adding your RSS feeds to my Google account.
Hi there, i read your blog occasionally and i own a similar one and i was just curious if you get a lot of spam responses? If so how do you stop it, any plugin or anything you can suggest? I get so much lately it's driving me insane so any support is very much appreciated.
There is perceptibly a lot to know about this. I suppose you made various nice points in features also.
Enjoyed reading this, very good stuff, appreciate it. "All things are difficult before they are easy." by John Norley.
This really answered my problem, thank you!
Sweet blog! I found it while browsing on Yahoo News. Do you have any suggestions on how to get listed in Yahoo News? I've been trying for a while but I never seem to get there! Thank you
Generally I do not learn post on blogs, but I would like to say that this write-up very pressured me to check out and do it! Your writing taste has been surprised me. Thank you, very great post.
I’d have to examine with you here. Which is not one thing I usually do! I take pleasure in reading a post that may make folks think. Additionally, thanks for permitting me to comment!
I rattling glad to find this site on bing, just what I was looking for : D besides bookmarked.
Greetings! I know this is kinda off topic nevertheless I'd figured I'd ask. Would you be interested in trading links or maybe guest writing a blog article or vice-versa? My website discusses a lot of the same topics as yours and I think we could greatly benefit from each other. If you're interested feel free to shoot me an email. I look forward to hearing from you! Great blog by the way!
Best online casino Australia real money 2025 – top picks for Aussies
愛壹帆海外版,专为华人打造的高清视频平台,支持全球加速观看。
海外华人必备的iyifan平台,提供最新高清电影、电视剧,无广告观看体验。
捕风捉影在线免费在线观看,海外华人专属平台,高清无广告体验。