0. 摘要
参加了天池的一个pdf简历信息提取的比赛,这里进行回顾、整理和分享
赛题要求从pdf简历中提取出信息,比如说名字,籍贯等。这里搭建了一个BiLSTM-CRF模型,能够从PDF简历中提取出所需的信息。
模型的线上得分是0.727,排名 21/1200+
1. 赛题相关
模型目标:pdf简历 --> 类别信息
2. 思路
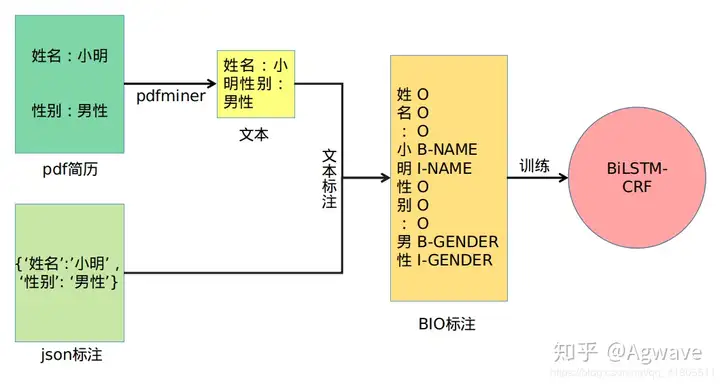
使用python库pdfminer,将pdf简历中的文本提取出来。利用json标注文件,对提取出来的文本进行匹配和BIO标注,每一个字对应一个标注。最后,将标注后的文本送到BiLSM-CRF模型中进行训练。
3. BiLSTM-CRF 模型
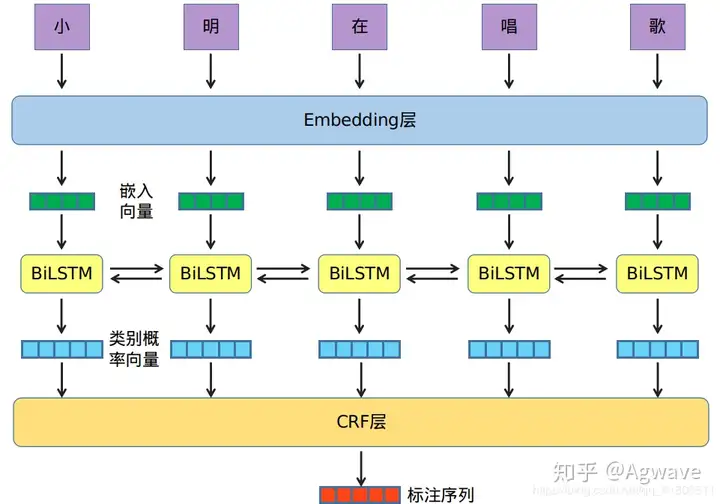
将文本中的每个字进行one-hot编码,经过Embedding层后,每一个字对应一个字向量,所以文本可以用一个矩阵表示。将文本矩阵输入BiLSTM层,输出中每一个字会对应一个类别概率向量,此类别概率向量表示了该字属于各个类别的概率。所以所有字属于各个类别的概率可以用一个类别概率矩阵表示。将此类别概率矩阵输入CRF层,即可得到得分最高的文本标注序列。
此处留一个pytorch官方的BiLSTM-CRF教程链接: https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html#
4. 代码地址
https://github.com/Agwave/PDF-Resume-Information-Extraction

文章评论
Well I definitely enjoyed studying it. This information procured by you is very helpful for good planning.
I adore reading and I believe this website got some really utilitarian stuff on it! .
After study a few of the blog posts on your website now, and I truly like your way of blogging. I bookmarked it to my bookmark website list and will be checking back soon. Pls check out my web site as well and let me know what you think.
Thanks, I have recently been looking for info approximately this topic for a long time and yours is the best I've found out so far. However, what concerning the bottom line? Are you positive in regards to the supply?
Some genuinely fantastic information, Sword lily I found this.
I besides conceive therefore, perfectly indited post! .
I'm curious to find out what blog platform you happen to be using? I'm experiencing some minor security issues with my latest website and I'd like to find something more secure. Do you have any recommendations?
I was very happy to search out this net-site.I wished to thanks on your time for this wonderful read!! I undoubtedly enjoying each little bit of it and I've you bookmarked to take a look at new stuff you weblog post.
great post, very informative. I wonder why the other experts of this sector do not notice this. You must continue your writing. I am confident, you have a great readers' base already!
Nice post. I was checking constantly this blog and I'm impressed! Very useful info particularly the last part :) I care for such info a lot. I was seeking this particular information for a very long time. Thank you and good luck.
obviously like your web site but you need to take a look at the spelling on quite a few of your posts. Several of them are rife with spelling problems and I find it very troublesome to tell the reality then again I will certainly come back again.
I think you have remarked some very interesting details , appreciate it for the post.
Hi there, I found your site via Google while looking for a related topic, your website came up, it looks great. I have bookmarked it in my google bookmarks.
Can I just say what a relief to find someone who actually knows what theyre talking about on the internet. You definitely know how to bring an issue to light and make it important. More people need to read this and understand this side of the story. I cant believe youre not more popular because you definitely have the gift.
Amazing blog! Is your theme custom made or did you download it from somewhere? A design like yours with a few simple adjustements would really make my blog shine. Please let me know where you got your theme. Kudos
Heya i’m for the first time here. I came across this board and I find It really useful & it helped me out a lot. I hope to give something back and aid others like you helped me.
Thank you for another informative web site. Where else could I get that type of info written in such an ideal way? I have a project that I'm just now working on, and I've been on the look out for such info.
Thank you for every other wonderful post. The place else may just anyone get that type of information in such a perfect means of writing? I've a presentation next week, and I am at the search for such info.
Hey there, I think your site might be having browser compatibility issues. When I look at your blog site in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, very good blog!
I'm curious to find out what blog platform you're working with? I'm experiencing some small security issues with my latest website and I would like to find something more secure. Do you have any recommendations?
Great ?V I should definitely pronounce, impressed with your site. I had no trouble navigating through all tabs and related info ended up being truly easy to do to access. I recently found what I hoped for before you know it at all. Reasonably unusual. Is likely to appreciate it for those who add forums or anything, website theme . a tones way for your customer to communicate. Excellent task..
You really make it seem so easy together with your presentation however I to find this topic to be actually one thing which I feel I'd never understand. It seems too complex and very extensive for me. I am having a look forward on your next submit, I’ll try to get the cling of it!
fantastic points altogether, you simply gained a brand new reader. What could you recommend in regards to your put up that you just made a few days in the past? Any certain?
You could definitely see your enthusiasm in the work you write. The world hopes for more passionate writers such as you who are not afraid to mention how they believe. At all times go after your heart.
What i do not realize is actually how you are not actually much more smartly-liked than you may be right now. You are so intelligent. You know thus considerably in relation to this topic, produced me in my opinion imagine it from numerous various angles. Its like men and women aren't interested until it¦s something to accomplish with Girl gaga! Your personal stuffs great. All the time handle it up!
Hello, you used to write fantastic, but the last few posts have been kinda boringK I miss your super writings. Past few posts are just a bit out of track! come on!
Hello there I am so grateful I found your blog page, I really found you by accident, while I was researching on Yahoo for something else, Anyways I am here now and would just like to say thanks a lot for a incredible post and a all round exciting blog (I also love the theme/design), I don’t have time to look over it all at the moment but I have book-marked it and also included your RSS feeds, so when I have time I will be back to read more, Please do keep up the excellent work.
Very nice post. I just stumbled upon your weblog and wished to say that I have truly enjoyed browsing your blog posts. After all I will be subscribing to your feed and I hope you write again very soon!
I got good info from your blog
Hi there, I found your site via Google while searching for a related topic, your web site came up, it looks great. I've bookmarked it in my google bookmarks.
Thank you for sharing with us, I believe this website truly stands out : D.
Some really tremendous work on behalf of the owner of this site, absolutely great content material.
I found your blog web site on google and test a few of your early posts. Continue to maintain up the excellent operate. I simply additional up your RSS feed to my MSN News Reader. Searching for ahead to reading extra from you afterward!…
Hey there! I know this is kinda off topic but I'd figured I'd ask. Would you be interested in exchanging links or maybe guest authoring a blog post or vice-versa? My blog discusses a lot of the same subjects as yours and I feel we could greatly benefit from each other. If you are interested feel free to send me an e-mail. I look forward to hearing from you! Great blog by the way!
超人和露易斯第三季高清完整官方版,海外华人可免费观看最新热播剧集。