0 前言
我不知道大家有没有和我一样的感受,很多论文里面的神经网络架构往往是通过一系列数学公式来表达,这本身没有问题,但对于初步想要完整了解整个网络架构的人来说,往往就要花比较多的时间去理解公式。
而当我在了解一个神经网络架构的时候,只有完全清楚输入到输出的完整过程,特别是张量维度变化的完整过程,才算认为自己确实了解了这个网络架构。所以我学习的时候往往希望有人能给我个例子,完整展示输入到输出的情况,让我能够更快地去理解论文的架构。我感觉可能也有人和我有同样的需求,所以这篇文章应运而生。这篇文章通过一个的例子,完整地展示 GCN 架构是如何将输入逐步转换为输出的。
如果大家觉得这种通过例子学习方式对自己帮助,请点赞或者评论让我知道,我会继续更新这种类型的文章。
1 GCN 层公式
一个 GCN 架构的是多个 GCN 层的堆叠,输入一层一层传播形成输出,接下来我们先围绕 GCN 层来说。
首先我们需要知道的是 GCN 前向传播的过程,就是在不断地在更新节点特征的过程。GCN 层的传播公式可以表述为:
\(H^{(l+1)} = \sigma (\widetilde{D}^{-\frac{1}{2}} \widetilde{A} \widetilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)})\)在这个公式中:
- \(H^{(l)}\) 表示第 \(l\) 层的节点特征矩阵,其维度通常是 \(N \times D_l\),其中 \(N\) 是节点的数量,\(D_l\) 是该层的特征维度。
- \(H^{(l+1)}\) 表示 \(l+1\) 层的输出特征矩阵,维度为 \(N \times D_{l+1}\)。
- \(W^{(l)}\) 是第 \(l\) 层的权重矩阵,用于执行线性变换,其维度为 \(D_l \times D_{l+1}\)。
- \(\sigma\) 是一个非线性激活函数,如 ReLU,它被应用于每个节点的特征上。
- \(\widetilde{A}\) 是邻接矩阵 \(A\) 的修正版本,通常会在 \(A\) 中添加自连接(即对角矩阵 \(I\),使得每个节点与其自身相连),表示为 \(\widetilde{A} = A + I\)。
- \(\widetilde{D}\) 是 \(\widetilde{A}\) 的度矩阵,即 \(\widetilde{D}_{ii} = \sum_j \widetilde{A}_{ij}\) , 并且\(\widetilde{D}^{-\frac{1}{2}}\) 是 \(\widetilde{D}\) 的平方根的逆矩阵,用于归一化,确保节点度数的影响在信息传递过程中得以平衡。
这个过程描述了在 GCN 层中,如何通过邻居节点的特征和权重矩阵,以及归一化的邻接关系来更新每个节点的特征表示。每一层的输出成为下一层的输入,从而允许信息在整个图结构中传播。可以直观理解为,更新当前节点的特征,需要同时考虑该节点的邻接关系以及邻居节点的特征。
2 GCN 层例子
假设现在有一份图数据如下
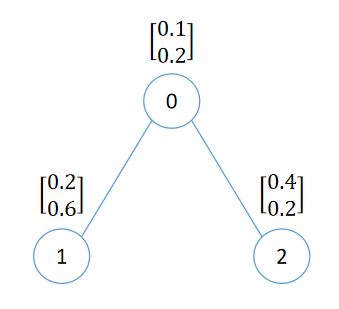
我们来看看对于这个图数据,\(H^{(l+1)} = \sigma (\widetilde{D}^{-\frac{1}{2}} \widetilde{A} \widetilde{D}^{-\frac{1}{2}} H^{(l)} W)\) 中右边的值都是什么。
从图中可以看到,
节点 0 的特征为 \(X_0 = \begin{bmatrix} 0.1 \\ 0.2 \end{bmatrix}\)
节点 1 的特征为 \(X_1 = \begin{bmatrix} 0.2 \\ 0.6 \end{bmatrix}\)
节点 2 的特征为 \(X_2 = \begin{bmatrix} 0.4 \\ 0.2 \end{bmatrix}\)
所以特征矩阵 \(X = \begin{bmatrix} 0.1 & 0.2 \\ 0.2 & 0.6 \\ 0.4 & 0.2 \end{bmatrix}\)
由上图的拓扑结构,可知邻接矩阵 A = \(\begin{bmatrix} 0 & 1 & 1 \\ 1 & 0 & 0 \\ 1 & 0 & 0 \end{bmatrix}\)
则 \(\widetilde{A} = A + I = \begin{bmatrix} 0 & 1 & 1 \\ 1 & 0 & 0 \\ 1 & 0 & 0 \end{bmatrix} + \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{bmatrix} = \begin{bmatrix} 1 & 1 & 1 \\ 1 & 1 & 0 \\ 1 & 0 & 1 \end{bmatrix}\)
由 \(\widetilde{D}_{ii} = \sum_j \widetilde{A}_{ij} \),得到 \(\widetilde{D} = \begin{bmatrix} 3 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2 \end{bmatrix}\),进而 \(\widetilde{D}^{-\frac{1}{2}} = \begin{bmatrix} \frac{1}{\sqrt{3}} & 0 & 0 \\ 0 & \frac{1}{\sqrt{2}} & 0 \\ 0 & 0 & \frac{1}{\sqrt{2}} \end{bmatrix}\)
由于 \(\widetilde{A}\) 和 \(\widetilde{D}^{-\frac{1}{2}}\) 都是固定的,我们不妨记 \(\widehat{A} = \widetilde{D}^{-\frac{1}{2}} \widetilde{A} \widetilde{D}^{-\frac{1}{2}}\),则有 \(H^{(l+1)} = \sigma (\widetilde{D}^{-\frac{1}{2}} \widetilde{A} \widetilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)}) = \sigma (\widehat{A} H^{(l)} W^{(l)})\)。
\(\widehat{A} = \widetilde{D}^{-\frac{1}{2}} \widetilde{A} \widetilde{D}^{-\frac{1}{2}} =\begin{bmatrix} \frac{1}{\sqrt{3}} & 0 & 0 \\ 0 & \frac{1}{\sqrt{2}} & 0 \\ 0 & 0 & \frac{1}{\sqrt{2}} \end{bmatrix}
\begin{bmatrix} 1 & 1 & 1 \\ 1 & 1 & 0 \\ 1 & 0 & 1 \end{bmatrix}
\begin{bmatrix} \frac{1}{\sqrt{3}} & 0 & 0 \\ 0 & \frac{1}{\sqrt{2}} & 0 \\ 0 & 0 & \frac{1}{\sqrt{2}} \end{bmatrix} =
\begin{bmatrix} \frac{1}{3} & \frac{1}{\sqrt{6}} & \frac{1}{\sqrt{6}} \\ \frac{1}{\sqrt{6}} & \frac{1}{2} & 0 \\ \frac{1}{\sqrt{6}} & 0 & \frac{1}{2} \end{bmatrix}\)
假设我们现在 \(l = 0\), 此时那么 \(H^{(l)} = H^{(0)}\),而 \(H^{(0)}\) 即是初始的特征矩阵 X。
初始节点特征维度为 2,所以 \(D_0 = 2\)。假设转换后的隐藏层特征维度 \(D_1 = 3\),那么 \(W^{(0)}\) 权重矩阵的维度为 \((D_0, D_1) = (2, 3)\)。
\(W^{(0)}\) 是随机初始化的参数矩阵,我们就设 \(W^{(0)} = \begin{bmatrix} 0.5 & 0.5 & 0.5 \\ 0.5 & 0.5 & 0.5 \end{bmatrix}\)。
我们现在开始来更新节点的特征。此时 \(H^{(0)} = X = \begin{bmatrix} 0.1 & 0.2 \\ 0.2 & 0.6 \\ 0.4 & 0.2 \end{bmatrix}\)
\(H^{(1)} = \sigma (\widetilde{D}^{-\frac{1}{2}} \widetilde{A} \widetilde{D}^{-\frac{1}{2}} H^{(0)} W^{(0)}) =\sigma (\widehat{A} H^{(0)} W^{(0)}) \\ =
\sigma (\widehat{A} X W^{(0)}) \\ =
\sigma \left (
\begin{bmatrix} \frac{1}{3} & \frac{1}{\sqrt{6}} & \frac{1}{\sqrt{6}} \\ \frac{1}{\sqrt{6}} & \frac{1}{2} & 0 \\ \frac{1}{\sqrt{6}} & 0 & \frac{1}{2} \end{bmatrix}
\begin{bmatrix} 0.1 & 0.2 \\ 0.2 & 0.6 \\ 0.4 & 0.2 \end{bmatrix}
\begin{bmatrix} 0.5 & 0.5 & 0.5 \\ 0.5 & 0.5 & 0.5 \end{bmatrix}
\right )\)
按上述值进行计算即可得到经过一层 GCN 层的输出 \(H^{(1)}\)。
至此,我们已经完全清楚了公式中每个变量的含义、维度、信息等,通过一层 GCN,我们得到了新的隐藏层特征 \(H^{(1)}\)。
3 多层 GCN 层的堆叠
前面我们已经完全清楚了公式中每个变量的含义、维度、信息等,通过一层 GCN,我们得到了新的隐藏层特征 \(H^{(1)}\)。而 GCN 神经网络就是 GCN 层的堆叠,从 \(H^{(0)}\) (即 \(X\)) 计算得到 \(H^{(1)}\),从 \(H^{(1)}\) 计算得到 \(H^{(2)}\),一层一层往下计算。
比如说对于两层 GCN,公式就是 \(H^{(2)} = \sigma (\widehat{A} H^{(1)} W^{(1)}) = \sigma (\widehat{A} (\sigma (\widehat{A} H^{(0)} W^{(0)})) W^{(1)})\)。
好了,这篇文章到这里就要结束了。最后再留一个问题,输出 \(H^{(l+1)}\) 的维度是由哪个变量决定的呢?

文章评论
$W^(l)$,感觉就是把表示向量发到MLP中走了一轮,只是计算方式不一样
There is noticeably a bundle to identify about this. I think you made various good points in features also.